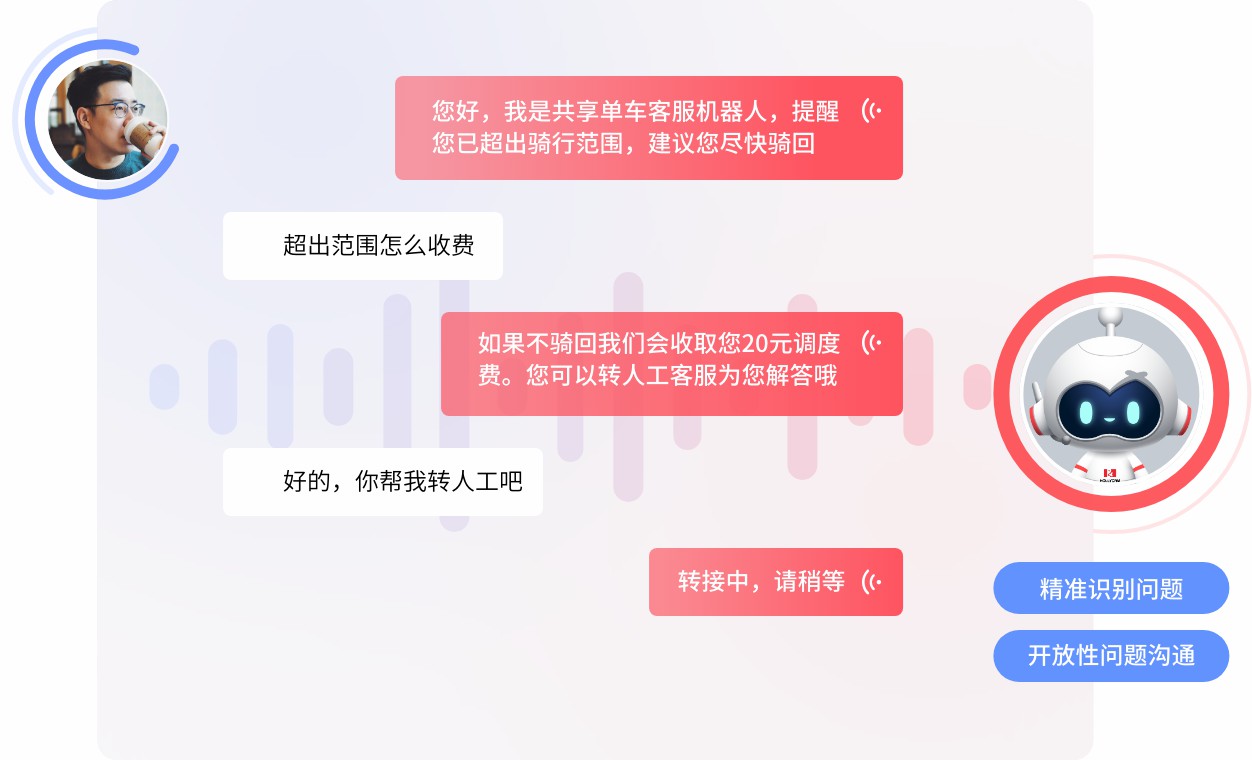
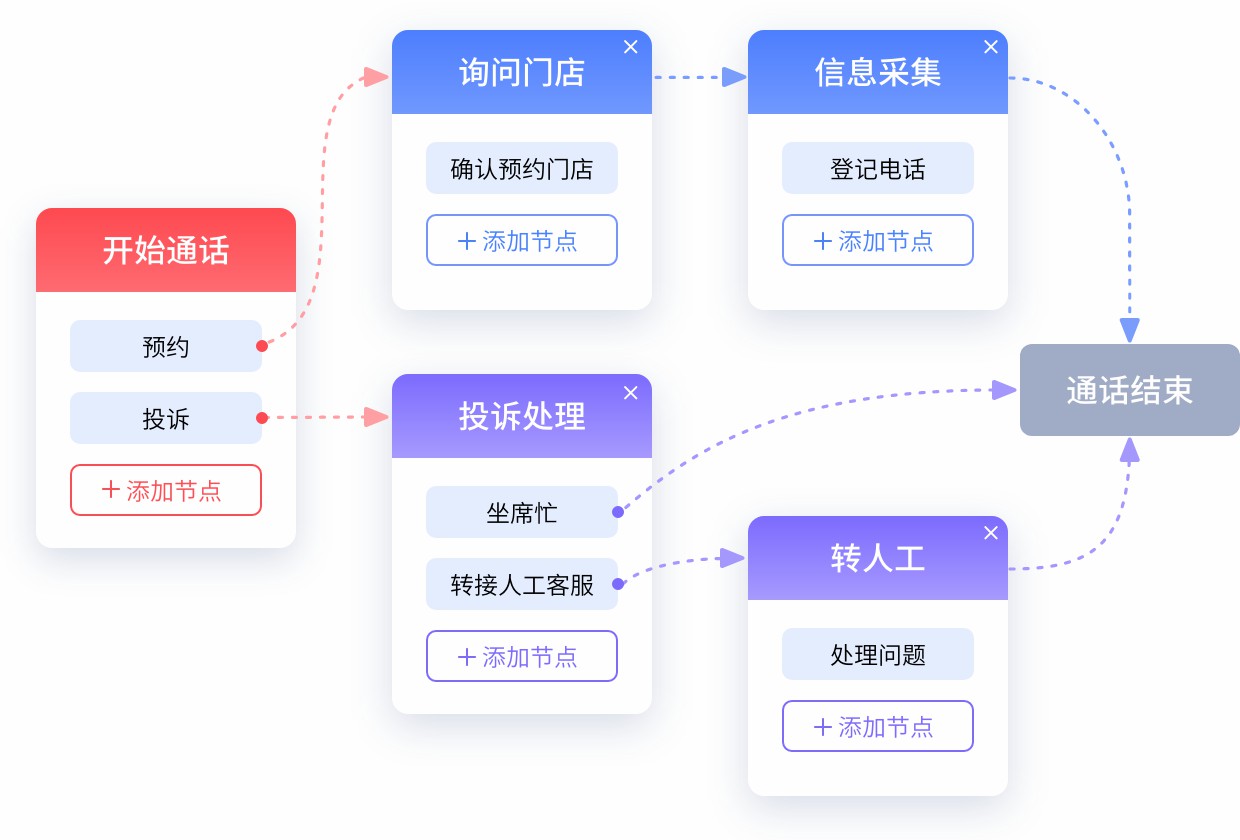
随着人工智能技术的持续演进,语音交互正逐步融入人们的日常生活。在客户服务领域,语音客服机器人凭借其便捷性与可扩展性,成为提升服务效率的重要工具。用户在实际使用中往往不满足于单次问答,而是期望通过连续的交互完成复杂任务,例如查询订单状态、修改账户信息或解决技术问题。这就对语音客服机器人提出了支持多轮对话的能力要求。
那么,语音客服机器人是否真正具备多轮对话能力?其背后依赖哪些技术原理?本文将从技术架构出发,深入剖析语音客服机器人实现多轮对话的关键环节、核心算法及面临的挑战,帮助读者全面理解这一智能交互系统的工作机制。
一、什么是多轮对话
(一)多轮对话的基本定义
多轮对话是指人与机器之间通过连续多次的言语交换完成特定目标的交互过程。与单轮问答(如“今天天气如何?”)不同,多轮对话通常涉及上下文依赖、信息递进和状态维护。例如,用户先说“我想查一下我的订单”,机器人回应“请提供订单号”,用户接着说“订单号是123456”,机器人再返回订单详情。整个过程中,每一句话都依赖前文信息,构成一个连贯的对话流。
(二)多轮对话的典型场景
在客户服务场景中,多轮对话广泛应用于以下情形:
信息补全:用户初始请求信息不完整,需通过追问获取必要参数(如地址、时间、账号等)。
任务分解:复杂操作被拆解为多个步骤,如“重置密码”需先验证身份、再设置新密码。
意图澄清:用户表达模糊时,系统通过反问确认真实需求(如“您是指物流延迟还是商品损坏?”)。
上下文延续:用户在对话中途切换子话题后返回主任务(如先问“运费多少”,再回到“那我下单吧”)。
这些场景均要求系统具备记忆、推理和状态跟踪能力,而非仅对孤立语句做出响应。
二、语音客服机器人的整体架构
要支持多轮对话,语音客服机器人需整合多个技术模块,形成端到端的处理流水线。其典型架构包含以下四个核心组件:
(一)语音识别(ASR)
语音识别(Automatic Speech Recognition, ASR)负责将用户的语音输入转换为文本。这是整个对话系统的入口。高质量的ASR需具备高准确率、低延迟和对口音、背景噪声的鲁棒性。在多轮对话中,ASR还需处理用户打断、重叠语音等复杂情况。
(二)自然语言理解(NLU)
自然语言理解(Natural Language Understanding, NLU)模块对ASR输出的文本进行语义解析,主要完成两项任务:
意图识别(Intent Detection):判断用户话语的目的,如“查询余额”“申请退款”。
槽位填充(Slot Filling):提取关键信息实体,如“金额:500元”“日期:2026年2月10日”。
NLU的准确性直接影响后续对话策略的选择。
(三)对话管理(DM)
对话管理(Dialogue Management, DM)是多轮对话的核心。它维护对话状态(Dialogue State),根据当前意图和已填充的槽位决定下一步动作,如继续询问缺失信息、执行业务逻辑或结束对话。DM通常包含两个子模块:
对话状态跟踪(DST):实时更新对话上下文,记录已完成和待完成的任务项。
对话策略选择(Policy):基于当前状态选择最优响应策略,如提问、确认或提供答案。
(四)自然语言生成与语音合成(NLG & TTS)
自然语言生成(Natural Language Generation, NLG)将DM决策的动作转化为自然流畅的文本回复。随后,语音合成(Text-to-Speech, TTS)将文本转换为语音输出,完成人机交互闭环。在多轮对话中,NLG需确保回复与上下文一致,避免重复或矛盾。
上述四个模块协同工作,共同支撑起完整的多轮对话能力。
三、多轮对话的关键技术原理
(一)对话状态表示
对话状态是多轮对话系统的“记忆中枢”。它通常以结构化形式存储当前会话的关键信息,包括:
已识别的用户意图
已填充的槽位及其值
对话历史摘要
当前任务进度(如“身份验证已完成,等待新密码输入”)
早期系统采用手工设计的状态模板,但难以覆盖复杂场景。现代方法多采用向量表示,将对话历史编码为固定维度的隐状态,便于神经网络处理。
(二)上下文建模
多轮对话依赖上下文理解。传统方法通过规则或有限状态机(FSM)管理上下文,但灵活性差。当前主流技术采用深度学习模型,如循环神经网络(RNN)、长短期记忆网络(LSTM)或Transformer,对对话历史进行编码。
例如,BERT等预训练语言模型可被微调用于对话理解任务,通过注意力机制捕捉远距离依赖关系。在语音客服中,系统需判断“它什么时候到?”中的“它”指代的是前文提到的“快递”还是“维修师傅”,这依赖于上下文建模能力。
(三)对话策略学习
对话策略决定了系统如何推进对话。传统方法依赖人工编写的规则树,如“若缺少订单号,则提问订单号”。这种方法可解释性强,但维护成本高,难以应对未预见的用户行为。
近年来,强化学习(Reinforcement Learning, RL)被广泛应用于对话策略优化。系统将对话视为马尔可夫决策过程(MDP),以任务完成率、用户满意度等为奖励信号,自动学习最优策略。例如,在订餐场景中,RL可学会优先询问“用餐时间”还是“送餐地址”,以最小化交互轮次。
(四)指代消解与省略恢复
用户在多轮对话中常使用代词(如“它”“那个”)或省略主语(如“改一下”),这对系统理解构成挑战。指代消解(Coreference Resolution)技术用于确定代词所指的实体,而省略恢复(Ellipsis Recovery)则补全缺失成分。
例如,用户说:“我订了机票。能改时间吗?”系统需推断“改时间”指的是“机票”的出发时间。这类任务通常结合句法分析、语义角色标注和上下文匹配来实现。
(五)错误恢复机制
在实际交互中,ASR或NLU可能出现错误,导致对话偏离轨道。健壮的多轮对话系统需具备错误检测与恢复能力。常见策略包括:
确认机制:对关键信息进行复述确认(如“您是要修改手机号1381234吗?”)
澄清提问:当置信度低时主动询问(如“抱歉,我没听清,请再说一遍”)
上下文回溯:允许用户纠正前文(如“不对,我说的是昨天的订单”)
这些机制显著提升系统的容错性和用户体验。
四、多轮对话的实现方式演进
(一)基于规则的系统
早期语音客服多采用基于规则的方法。开发者预先定义所有可能的对话路径,每个节点对应一个状态,用户输入触发状态转移。例如:
状态A:询问订单号 → 若用户提供 → 转至状态B;否则重复询问。
状态B:查询数据库 → 返回结果 → 结束。
此类系统逻辑清晰,但扩展性差。每新增一个业务场景,需重新编写大量规则,且难以处理用户自由表达。
(二)基于统计模型的系统
随着机器学习发展,统计模型被引入对话系统。NLU模块采用分类器(如SVM、随机森林)识别意图,槽位填充使用序列标注模型(如CRF)。对话管理则通过概率图模型(如POMDP)建模不确定性。
这类方法在一定程度上提升了泛化能力,但仍依赖大量标注数据,且模块间误差会逐级传播。
(三)端到端神经对话系统
近年来,端到端(End-to-End)神经网络成为研究热点。整个对话系统被建模为一个黑箱模型,直接从用户输入生成系统回复,无需显式划分NLU、DM、NLG等模块。
代表性模型包括Seq2Seq、Memory Networks和基于Transformer的架构。其优势在于可自动学习对话模式,减少人工干预。然而,端到端系统存在可控性差、难以集成业务逻辑、训练数据需求大等问题,在工业级客服场景中尚未完全取代模块化架构。
目前,主流实践多采用“模块化+神经增强”的混合架构:关键环节(如NLU、DM)保留结构化设计以确保可靠性,同时引入神经网络提升语义理解与生成质量。
五、多轮对话面临的技术挑战
尽管技术不断进步,语音客服机器人在实现高质量多轮对话时仍面临诸多挑战。
(一)语义歧义与意图漂移
用户语言常含模糊、歧义或隐含意图。例如,“我上次买的不行”可能指商品质量、物流速度或售后服务。更复杂的是,用户可能在对话中改变主意(如从“退货”转为“换货”),即意图漂移。系统需动态调整对话策略,这对状态跟踪提出高要求。
(二)长程依赖与上下文遗忘
在超过5轮的对话中,早期信息易被遗忘。虽然注意力机制可缓解此问题,但计算开销大。如何高效压缩和检索长期上下文,仍是研究难点。
(三)个性化与情感感知缺失
当前系统多采用通用模型,缺乏对用户画像、历史行为或情绪状态的感知。例如,面对焦急的用户,系统若仍机械地按流程提问,易引发不满。融合情感计算与个性化推荐,是提升体验的重要方向。
(四)多任务与多域切换
用户可能在同一对话中涉及多个业务领域(如先查账单,再报修)。系统需具备跨域理解与任务切换能力,避免混淆上下文。这要求对话状态表示具有高度灵活性。
(五)数据隐私与安全合规
多轮对话涉及大量用户个人信息。如何在保障数据安全的前提下实现高效状态跟踪,需严格遵循隐私保护规范,如数据脱敏、本地化处理等。
六、未来发展趋势
(一)大模型驱动的对话理解
大型语言模型(LLM)展现出强大的上下文理解和生成能力。通过提示工程(Prompt Engineering)或微调,LLM可作为NLU或NLG模块的增强器,甚至承担部分对话管理功能。其零样本或少样本学习能力,有助于降低对标注数据的依赖。
(二)知识增强对话系统
将外部知识库(如产品手册、FAQ)与对话系统深度融合,可提升回答准确性。例如,当用户询问“这款手机支持快充吗?”,系统可实时检索知识库并生成精准回复,而非依赖预设脚本。
(三)多模态交互融合
未来语音客服或融合视觉、触觉等多模态信息。例如,用户上传故障图片后,系统结合图像识别与语音对话进行诊断。这种多模态协同将进一步丰富交互维度。
(四)可解释性与可控性提升
为增强用户信任,系统需提供决策依据(如“我之所以问您的身份证号,是为了验证账户安全”)。同时,通过人机协作机制,允许人工客服无缝介入复杂对话,形成“AI+人工”的混合服务模式。
结语:
语音客服机器人是否支持多轮对话?答案是肯定的,但其实现并非简单功能叠加,而是依赖语音识别、自然语言理解、对话管理与语音合成等多个技术模块的精密协同。从早期的规则系统到如今的神经网络增强架构,多轮对话技术已取得显著进展,能够处理信息补全、任务分解、意图澄清等典型场景。然而,语义歧义、长程依赖、个性化缺失等挑战依然存在。
未来,随着大模型、知识增强和多模态技术的发展,语音客服机器人有望实现更自然、高效、可信的多轮对话体验。理解其技术原理,不仅有助于合理预期系统能力,也为相关领域的研究与应用提供坚实基础。