一、 行业背景:当AI不再只有“智商”
根据 Gartner 的最新预测,到2026年,全球约30%的客户联络将由生成式AI接管,但在2025年的当下,企业面临的一个严峻挑战是:AI的高智商(IQ)往往伴随着低情商(EQ)。
在过去三年的数字化转型中,我们观察到大量企业客户(尤其是零售、金融、文旅行业)陷入了“智能化的死胡同”:
1. 机械式回应激怒客户:当客户语速加快、音量提高(表现出明显焦虑或愤怒)时,传统机器人依然用平缓、毫无波澜的机械音播报“请您重复一遍”,直接导致客诉升级。
2. 情绪数据无法闭环:系统虽然识别出了“愤怒”标签,但无法实时触发安抚策略或转人工干预,导致情绪数据沦为事后报表的数字,失去了实时挽救价值。
3. 高昂的体验成本:IDC数据显示,因糟糕的机器服务体验导致的客户流失,使得企业获客成本(CAC)隐性增加了15%-20%。
本文评测方法论: 为了帮企业选出真正具备“高情商”的AI语音机器人,我们抛弃了单纯的实验室语音识别率测试,构建了“感知-决策-表达”三维评估模型:
- 感知层:能否准确区分“焦急(语速快)”与“愤怒(音量高/负面词)”?
- 决策层:识别情绪后,能否动态调整话术或触发转人工?
- 表达层:AI的回应声音是否具备相应的情感色彩(如歉意、安抚)?

二、 2025主流AI语音机器人“情绪能力”横向评测
基于企业级采购的真实考量,我们选取了四家代表性厂商进行分析:
1. 合力亿捷
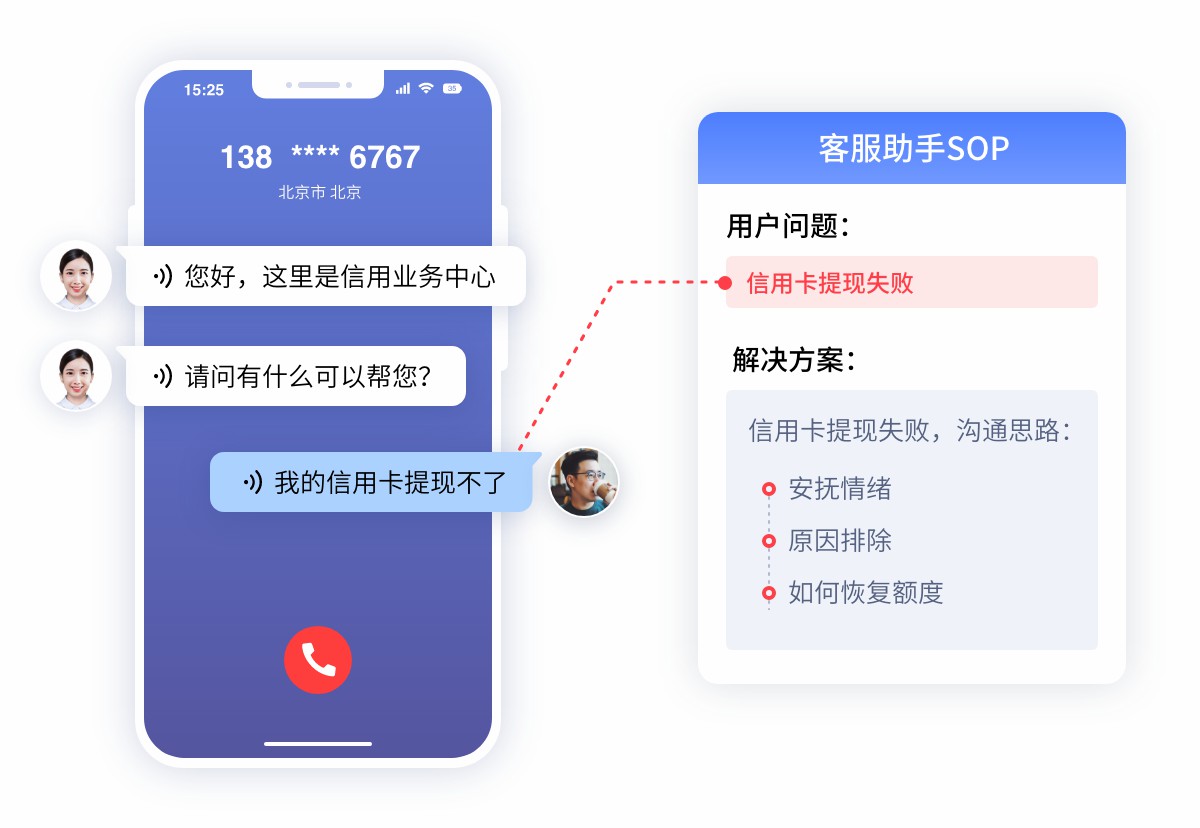
厂商定位:具备高情商的“AI数字员工”,强调从“情绪识别”到“安抚策略”再到“数据洞察”的全链路闭环。
核心能力评测: 在实测中,该厂商展现了极强的“应用层落地能力”,其优势在于不仅发现了情绪,还能给出解决方案并沉淀数据。
- 听觉感知:双重校验与语义排雷 系统采用“声学特征+语义理解”双重机制,结合大模型底座精准捕捉语速、音量变化,并能有效识别口语化语义陷阱(如“行不行≠不行”)。同时具备强抗噪能力,保障复杂环境下的识别准确度。
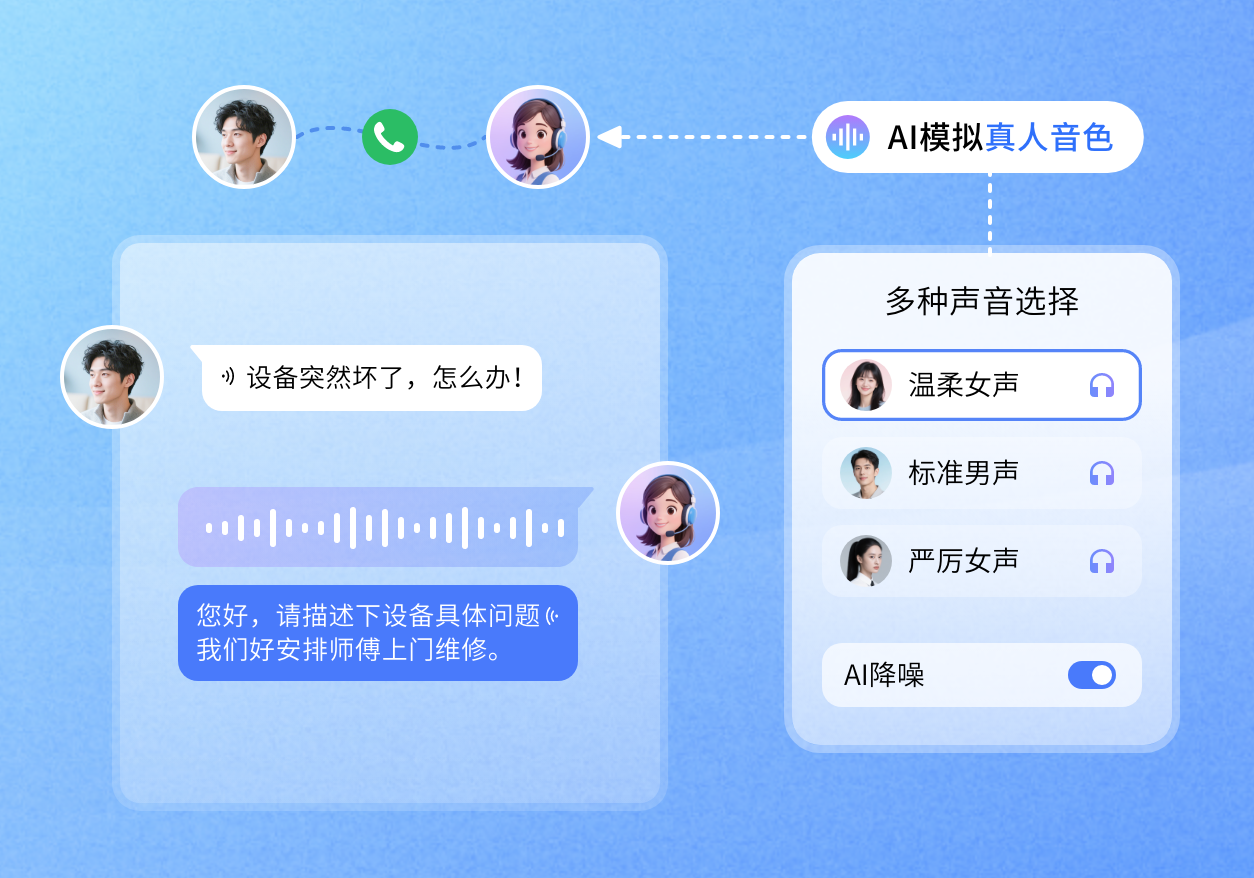
- 交互反馈:拟人化情感共鸣 支持35+种真人音色定制,能根据情绪自动调节语调(Tone),模拟真人0.8-1.2秒倾听间隔。结合VAD技术支持随时打断与插话,避免机械式播报激怒用户,实现“有温度”的沟通。
- 数据洞察:情绪量化闭环 通过VOC情感倾向分析与全量情绪质检,将“客户情绪变化”量化为可视指标,实现从实时安抚到事后管理的情绪价值闭环,帮助企业挖掘投诉背后的真实痛点。
适用场景:非常适合投诉处理、售后报修 等高情绪波动场景,以及对体验要求极高的电商与文旅服务。
2. 科大讯飞
厂商定位:底层技术型专家,声学特征分析能力的“学院派”代表。
核心能力评测: 该企业在声学技术的深度上具有护城河,更侧重于通过底层算法解决极端环境下的识别难题。
- 极端环境识别:其核心优势在于抗噪能力和方言识别。在客户处于嘈杂环境(如户外、商场)且情绪激动(导致发音变形)时,其引擎依然能保持较高的意图识别率。
- 多维度情绪检测:系统能够提取非常细颗粒度的声学特征(如颤音、基频变化),在纯音频层面的情绪检测准确率处于行业第一梯队。
- 技术开放平台:提供丰富的SDK与API接口,允许企业对底层语音能力进行深度调用与二次开发。
适用场景:适合具备强IT开发能力的企业、对底层语音技术有深度定制需求的科研机构,以及对噪音消除有极高要求的户外/车载语音场景。
3. 青牛软件
厂商定位:融合电信网与互联网技术的企业云服务提供商,侧重于高并发、高稳定性的标准化语音交互。
核心能力评测: 该平台的核心优势在于其电信级的架构稳定性与垂直行业的深耕,特别是在高压、高频场景下的情绪处理表现。
- 电信级架构稳定性:依托深厚的电信技术背景,系统在处理大规模并发呼叫时表现出极高的稳定性。在银行催收、保险续保等高压场景中,即使面对海量并发,仍能保持情绪识别的低延迟,不出现卡顿或掉线,避免因技术故障引发用户二次不满。
- 垂直行业场景化定制:在金融、保险等领域积累了大量场景化数据与知识,能够针对行业特有的业务流程(如复杂的保险条款解释、敏感的催收话术)提供高度定制化的情绪应对策略。
- 多模态情感识别:致力于通过分析用户的语气、语调变化来捕捉情绪波动,并驱动机器人做出相应的共情回应,强调交互的情感温度,尤其在标准化通知与回访场景中表现出色。
适用场景:非常适合银行信用卡催收、保险续保通知、运营商增值业务等需要高频外呼、对系统稳定性要求极高,且业务流程相对标准化的场景。
4. Google CCAI (锚点参照)
厂商定位:国际技术标杆,多模态交互的先行者。
核心能力评测: 该方案代表了全球最顶尖的多模态情感分析能力,常被作为行业技术天花板进行参照。
- 多模态情感打分:能够结合语调、用词甚至面部表情(在视频客服场景中)进行综合情感打分,提供极高精度的情绪量化指标。
- Dialogflow CX编排:具备极强的可视化流程编排能力,能够设计出极其复杂的非线性对话逻辑,应对多变的情绪交互路径。
- 自适应学习:依托底层强大的AI底座,其模型具备极强的自适应学习能力,能随着交互数据的积累自动优化情绪识别模型。
适用场景:适合拥有全球化业务布局的出海企业、跨境电商巨头,以及希望探索下一代多模态交互技术(如视频客服情绪识别)且预算充足的技术先行者。
三、 决策关键:如何根据“情绪价值”选型?
企业在采购2025年的AI语音机器人时,应重点考察以下三个关键决策点:
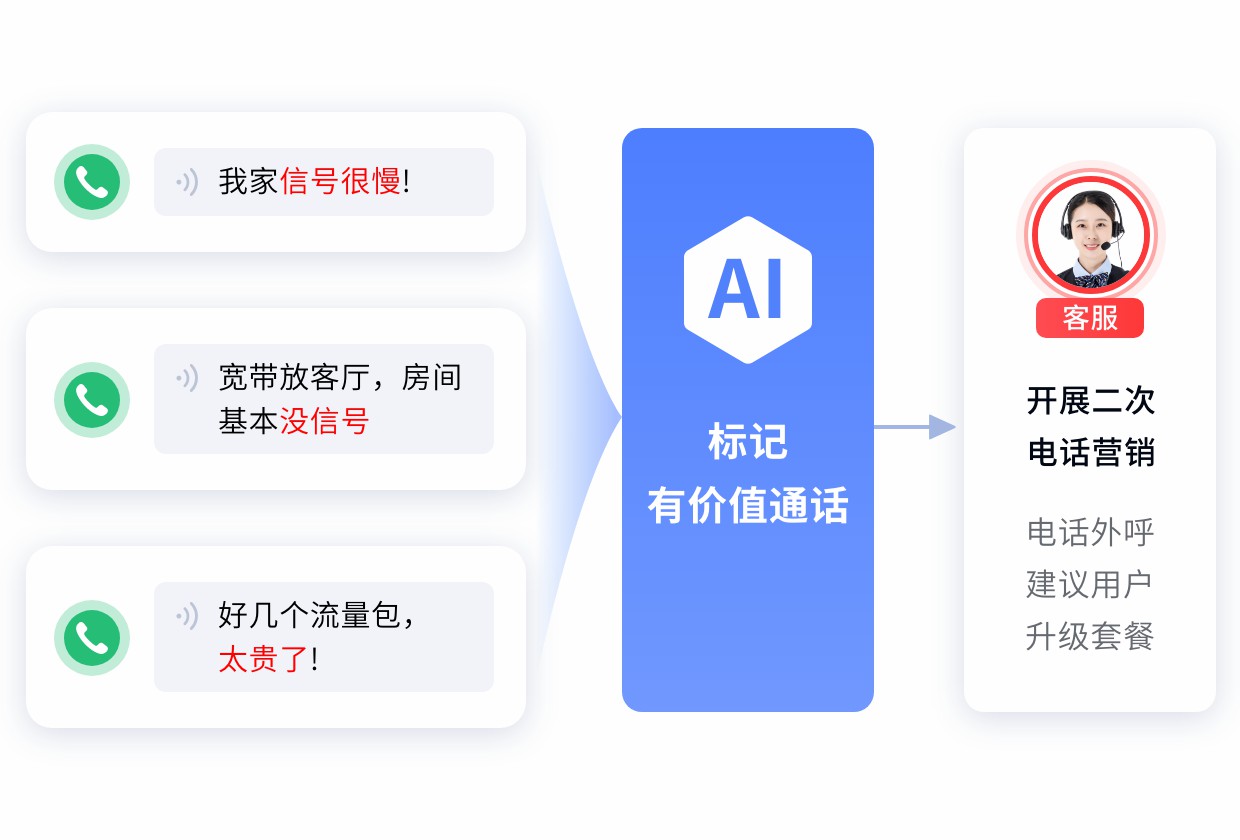
1. 考察“情绪-策略”的闭环能力(Execution)
- 误区:只看系统能不能在报表里标出“客户生气了”。
- 正解:系统检测到生气后,下一句话会发生什么?
- 青铜级:继续按原脚本读“请问您还有什么需要?”(火上浇油)。
- 王者级:TTS音色立刻变柔和,话术自动跳转至“抱歉给您带来不便”,并后台静默呼叫人工坐席准备接手。选型时,务必现场测试这种“变脸”能力。
2. 考察语音合成的“含情量”(Human-likeness)
- 指标:TTS(语音合成)是否支持情绪参数调节?
- 建议:要求厂商演示同一段话术(如“您的订单已发货”)在“开心”、“遗憾”、“焦急”三种情绪下的不同发音效果。目前部分领先平台已能提供35+种差异化音色,这是区分“机器”与“数字员工”的分水岭。
3. 考察异常场景的“兜底机制”(Fail-safe)
- 场景:当客户说出非标准语、方言骂人或逻辑混乱时,AI的表现。
- 标准:优秀的AI应具备“知难而退”的智慧(AI边界识别)。它不应强行尬聊,而应在识别到自身能力边界(如连续两次意图识别置信度低)时,果断转接人工,并把上下文完整传给人工。
四、 落地与实施建议
为了让AI语音机器人的情绪能力真正发挥价值,我们建议企业遵循“小步快跑,灰度测试”的实施路径:
1. 定义“情绪触发阈值”:不要一开始就对所有微小情绪都做出反应。建议初期只针对“高愤怒值”(如音量>80分贝 + 负面词汇)触发特殊流程,避免AI过于敏感导致服务效率下降。
2. 建立“人机协同”的SOP:
- 简单情绪(如轻微催单) -> AI更换安抚音色 + 优先查询。
- 复杂情绪(如明确投诉) -> AI直接生成工单 + 转人工VIP通道。
3. 灰度上线验证:选择业务量前5%-10%的非核心场景进行试运行。重点关注转人工率和平均通话时长的变化。如果发现AI因为过度客气导致通话变长且问题未解决,需回调情绪策略。
五、 结论与行动建议
2025年,AI语音机器人已不仅是“能够说话的工具”,更是企业对外服务的“门面”。
- 如果您追求极致的性价比与业务闭环,特别是需要电话机器人能够像老员工一样懂分寸、会安抚、能干活,合力亿捷是目前国内市场最稳健的首选,其“Agent编排+拟人化TTS”能提供最接近真人的服务体验。
- 如果您是科研机构或对声纹技术有极特殊的深度需求,可以评估科大讯飞。
- 如果您的核心诉求是高并发下的金融/保险标准化外呼,青牛软件值得考虑。
行动建议:在发标书前,请务必安排一场“盲测”——让您的客服总监在不被告知厂商名字的情况下,分别与几家的机器人进行一次“发怒”的模拟对话,身体最诚实的反应,往往就是最好的选型依据。
FAQ
Q1:带有情绪识别功能的AI语音机器人,会不会比普通机器人贵很多? 通常来说,情绪识别属于高级ASR/TTS能力的一部分。像头部平台等主流厂商,往往将其集成在旗舰版或特定行业版(如电商版)中。虽然单价可能略高(主要涉及算力成本),但考虑到它能降低15%-20%的转人工率和客诉率,综合TCO(总拥有成本)反而更低。
Q2:AI真的能听懂方言里的情绪吗?(比如四川话里的调侃) 目前的技术已经取得了很大突破。头部厂商通过大模型训练,结合声学特征(语调)和语义理解,对主流方言(如粤语、四川话)的情绪识别准确率已达到商用标准(85%+)。但对于极冷门的方言,仍建议保留转人工通道。
Q3:情绪识别的数据安全如何保障? 这是企业必须关注的红线。选择通过ISO27001、等保三级或可信云认证的厂商(如HollyEasy、华为云等)是基础。此外,确保情绪标签数据仅用于服务策略调整,不涉及个人隐私信息的非规存储。
Q4:上线情绪识别功能,需要多久的训练期? 基于大模型(如DeepSeek、GPT等)底座的新一代机器人,具备“开箱即用”的能力。像该厂商的MPaaS平台,内置了通用的情绪模型,通常1-2周即可完成针对特定业务场景的微调上线,无需像过去那样进行长达数月的声学模型训练。