人工智能技术的普及,让语音电话机器人成为人机交互的常见载体。不同于固定语音播报设备,智能语音机器人可适配人类随意的口语表达,完成多轮沟通应答。大众普遍好奇机器听懂人话的核心逻辑,本文从底层技术出发,完整拆解ASR、NLU等核心模块,梳理多轮对话的完整技术链路。
一、AI语音电话机器人交互核心逻辑与整体技术架构
(一)人机语音交互的核心难点
人类日常电话沟通的口语表达具备极强的随意性,不存在固定句式与规范语法。对话中普遍存在语气词、停顿、重复、口误、语序颠倒等情况,同时包含轻重音、语速快慢、情绪起伏等语音特征。不同于书面文字的规整统一,口语内容碎片化、自由化,这对机器识别与理解提出了极高要求。
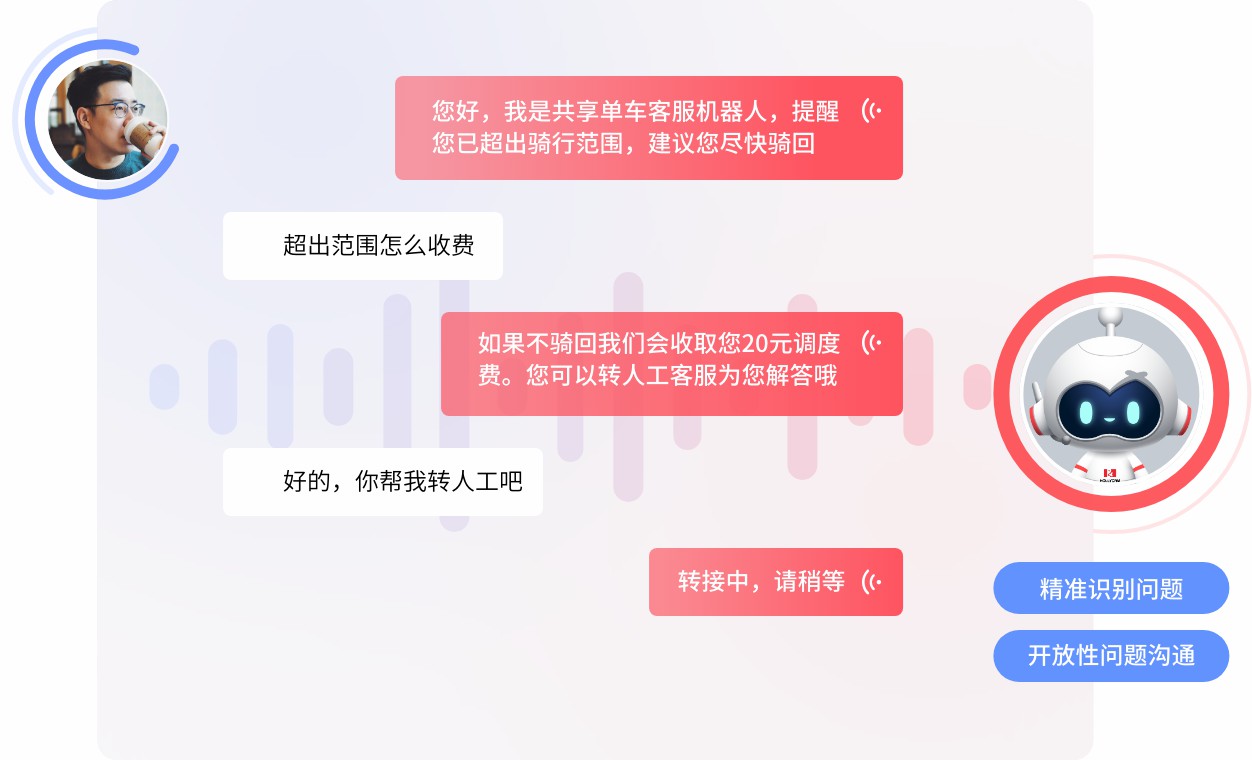
传统语音设备仅能识别固定关键词、触发预设语音,无法适配自由对话场景。而AI语音电话机器人的核心突破,就是摆脱了固定规则的限制,能够适配多样化的人类口语表达,精准捕捉对话意图,完成连贯的多轮交互,实现接近人工沟通的对话效果。
整体来看,机器听懂人话的核心难点集中在两大维度,一是“听得清、转得准”,即将杂乱的语音信号精准转化为标准文本;二是“读得懂、接得上”,即理解文本背后的真实语义,结合上下文完成连续应答,这也是ASR与NLU两大核心技术的核心价值所在。
(二)全链路技术架构整体框架
AI语音电话机器人的多轮语音交互并非单一技术实现,而是一套层层递进、环环相扣的完整技术链路。整个交互流程遵循“信号采集—语音处理—文本转化—语义理解—对话决策—语音输出”的逻辑闭环,各模块独立运作又深度协同。
完整技术链路主要包含六大核心模块,依次为语音信号采集模块、语音预处理模块、ASR自动语音识别模块、NLU自然语言理解模块、DMS对话管理模块、TTS语音合成模块。除此之外,还搭配有上下文存储、语义纠错、意图兜底等辅助模块,保障复杂对话场景的稳定运行。
简单来说,整个交互过程可以分为感知、理解、决策、输出四个阶段。感知阶段依托硬件与预处理技术捕捉人类语音;理解阶段依靠ASR转写、NLU解析语义;决策阶段由对话管理模块判断应答逻辑;输出阶段通过TTS技术生成语音反馈,完成单次交互,多轮交互则是该闭环的持续迭代。
合力亿捷Synerow AI呼叫中心系统,基于 MPaaS 智能体编排平台,覆盖电话语音+在线+工单全渠道全栈能力,采用全栈 Agentic 原生架构,通过 SaaS/混合云/私有化/HollyONE 一体机 4 种部署方案,适配中小型到超大型企业。
二、感知层:从人声到文本,ASR语音识别核心技术解析
ASR自动语音识别技术是AI语音电话机器人的“耳朵”,是整个人机交互链路的入口。所有人类语音对话内容,都需要经过ASR模块处理,将无形的语音信号转化为有形的结构化文本,为后续语义理解提供基础素材。没有精准的ASR转写,后续所有语义解析与对话决策都无从谈起。
(一)语音信号采集与预处理
电话场景下的语音信号存在明显特殊性,通话链路中会存在线路杂音、环境噪音、信号波动等干扰因素,同时人声频率、音量、语速差异极大。未经处理的原始语音信号杂乱无序,无法直接用于识别计算,必须先完成预处理操作,净化有效语音信号。
1、信号降噪处理。该步骤的核心作用是剥离环境噪音、线路底噪、电流杂音等无效信号,保留纯净的人类语音信号。通过算法区分人声频率与噪音频率,过滤非人声干扰波段,同时弱化通话过程中的突发杂音,保障语音信号的完整性与纯净度。
2、语音分帧处理。人类语音是连续变化的模拟信号,计算机无法直接识别连续信号,需要将其切割为短暂、固定长度的语音帧。分帧操作可以将动态的语音信号转化为静态的帧数据,方便后续逐帧分析特征,同时适配人类口语的停顿、断句特征。
3、特征提取处理。预处理的核心核心步骤,通过专业算法提取语音的核心特征参数,摒弃无效的冗余信号。重点提取人声的梅尔频率倒谱系数等核心特征,这类特征与人耳听觉感知逻辑高度契合,能够精准表征人声的音色、音调、语速等核心信息,为ASR模型识别提供核心依据。
(二)ASR模型核心识别原理
完成预处理与特征提取后,ASR深度学习模型会对特征数据进行运算分析,实现语音到文本的精准转化。现代AI语音机器人所使用的ASR模型,均基于深度神经网络架构搭建,摆脱了传统模板匹配、规则匹配的局限性,具备更强的泛化能力。
1、声学模型运算。声学模型是ASR的基础核心模块,核心作用是建立语音特征与发音单元的对应关系。模型通过海量语音数据训练,学习不同人声、不同语速、不同口音对应的发音特征,能够将提取的语音特征帧,精准映射为对应的音节、音素等基础发音单元。
声学模型的核心优势在于适配性极强,能够兼容日常口语中的轻微咬字不清、语速过快、轻声连读等情况,不会因为细微的发音偏差导致识别错误,大幅提升电话场景下的识别稳定性。
2、语言模型校正。仅依靠声学模型容易出现同音字词识别错误,语言模型的作用就是结合语言逻辑、词汇搭配、语法习惯,对声学模型的初步识别结果进行校正优化。模型依托海量文本语料训练,掌握自然语言的搭配规律与句式逻辑,筛选出符合语境的最优文本结果。
3、解码输出文本。解码模块整合声学模型与语言模型的运算结果,对所有可能的识别结果进行概率排序,剔除歧义内容,输出最贴合用户口语表达的标准文本。最终输出的文本会完成基础的断句、纠错处理,保证文本内容通顺、语义完整。
(三)电话场景ASR的适配优化逻辑
通用场景的ASR技术无法直接适配电话语音交互需求,电话语音存在带宽有限、信号压缩传输、人声单一、杂音特殊等专属特征,因此语音电话机器人的ASR模块会做针对性优化,适配通话场景特性。
1、窄带语音适配优化。电话通话采用窄带语音传输模式,人声高频信息会被压缩,导致部分发音特征模糊。专用ASR模型针对窄带语音特征完成专项训练,能够在语音信息不完整的情况下,精准还原用户口语内容,避免识别失真。
2、口语化识别优化。针对口语中的语气词、重复语句、停顿卡顿、口误修正等场景,模型具备专项处理能力,可自动过滤无效语气词、合并重复语义内容、修正口语口误,输出简洁、准确的有效文本内容。
3、实时流式识别优化。电话对话是实时连续的交互过程,ASR模块采用流式识别架构,无需等待用户说完整句话即可逐段识别、实时输出文本,有效降低交互延迟,保障人机对话的流畅度,贴合自然沟通节奏。
三、理解层:从文本到语义,NLU自然语言理解核心技术
ASR技术解决了“听见声音、转化文字”的问题,但文字本身不具备语义属性,单纯的文本内容无法让机器判断用户需求。NLU自然语言理解技术是AI语音电话机器人的“大脑”,核心作用是对ASR输出的文本进行深度解析,读懂文本背后的真实意图、核心诉求与关键信息,是机器真正“听懂”人话的核心关键。
(一)NLU技术的核心定位与处理流程
NLU是自然语言处理的核心分支,聚焦于机器对人类自然语言的语义理解,区别于简单的关键词匹配,能够理解语境、歧义、隐含语义等复杂语言内容。在语音电话机器人链路中,NLU承接ASR的文本输出,为后续对话决策提供核心依据。
NLU的整体处理流程分为文本预处理、基础语义解析、深度意图理解、信息结构化输出四个步骤,全程依托深度学习模型完成自动化运算,无需人工干预,能够快速适配各类口语化文本内容。
文本预处理是NLU的前置基础,主要对ASR输出的文本进行标准化处理,包括剔除无效字符、统一句式格式、修正识别误差、拆分长句等操作,将口语化、碎片化的文本转化为规整的可解析文本,提升后续语义解析的精准度。
(二)NLU核心基础解析能力
1、分词与词性标注。中文语言不存在天然的词语分隔符,这是中文语义理解的首要难点。NLU模型通过精准的分词算法,将连续的文本拆分为独立的词语、短语单元,同时对每个单元进行词性标注,区分名词、动词、形容词、副词等基础词性,搭建文本的基础语义结构。
分词与词性标注是所有语义理解的基础,能够让机器区分文本中的主体、动作、修饰信息,避免出现语义混淆。针对口语化的不规范句式、倒装句式、省略句式,模型也能完成精准分词与词性判定,适配日常对话场景。
2、句法与语义依存分析。完成分词标注后,模型会进一步分析文本的句法结构,梳理词语之间的语义依存关系,判断语句的主谓宾结构、逻辑关系、修饰关系。通过句法分析,机器能够读懂完整的语句逻辑,区分核心信息与次要修饰信息。
该能力可以有效解决口语歧义问题,针对同一语句的多重含义、不同语序的同类语义,模型能够依托句法结构精准判定真实语义,避免因句式不规范导致理解偏差。
(三)NLU核心能力:意图识别与实体抽取
意图识别与实体抽取是NLU技术的两大核心核心能力,也是语音电话机器人实现精准应答的核心支撑,直接决定机器是否能听懂用户的核心诉求。
1、意图识别。意图识别的核心作用是判断用户整段对话的核心目的,归类用户需求类型。人机电话对话中,用户的所有口语表达都对应明确的核心意图,咨询、核实、提问、确认、异议等均为常见对话意图。
传统规则式机器人依托固定关键词匹配意图,容易出现识别偏差,而深度学习驱动的NLU模型,能够依托上下文语义判断整体意图,不局限于单一关键词。即使用户表达句式不同、用词不同,只要核心诉求一致,模型均可精准识别对应意图。
同时,模型支持模糊意图识别,针对用户表达不完整、诉求模糊、语义隐晦的场景,能够结合语境推断核心需求,避免出现无法应答的情况,提升对话适配性。
2、实体抽取。意图识别解决“用户想做什么”的问题,实体抽取解决“用户针对什么内容提问”的问题。实体是对话中具备实际业务价值的关键信息,是支撑对话落地的核心要素。
NLU模型能够从碎片化的口语文本中,精准提取各类关键实体信息,同时区分不同实体的属性与含义。针对口语中省略实体、倒装表述、穿插无关内容的场景,模型可精准筛选有效实体信息,过滤无效干扰内容。
实体抽取的精准度直接决定对话的有效性,机器通过提取核心实体,结合识别的用户意图,能够完整还原用户的精准诉求,为后续对话决策、内容应答提供精准的数据支撑。
(四)NLU歧义消解与语境适配能力
人类自然语言存在大量歧义内容,同音异义、一词多义、句式模糊、语义隐含等情况普遍存在,这是机器语义理解的最大难点。优质的NLU模型具备完善的歧义消解能力,可依托语境完成精准语义判定。
1、词汇歧义消解。针对中文中普遍存在的多义词、近义词,模型结合整句语境与对话场景,判定词语在当前语句中的具体含义,避免词汇语义混淆导致的理解错误。
2、句式歧义消解。针对口语中无标点、省略成分、语序混乱的不规范句式,模型依托句法分析与语义逻辑,补全缺失信息、梳理正确句式逻辑,还原用户真实表达的语义内容。
3、场景语境适配。NLU模型可适配电话对话的专属场景逻辑,结合通用沟通常识与场景对话习惯,修正语义偏差,精准捕捉用户隐含的诉求,实现超越字面文字的深度语义理解。
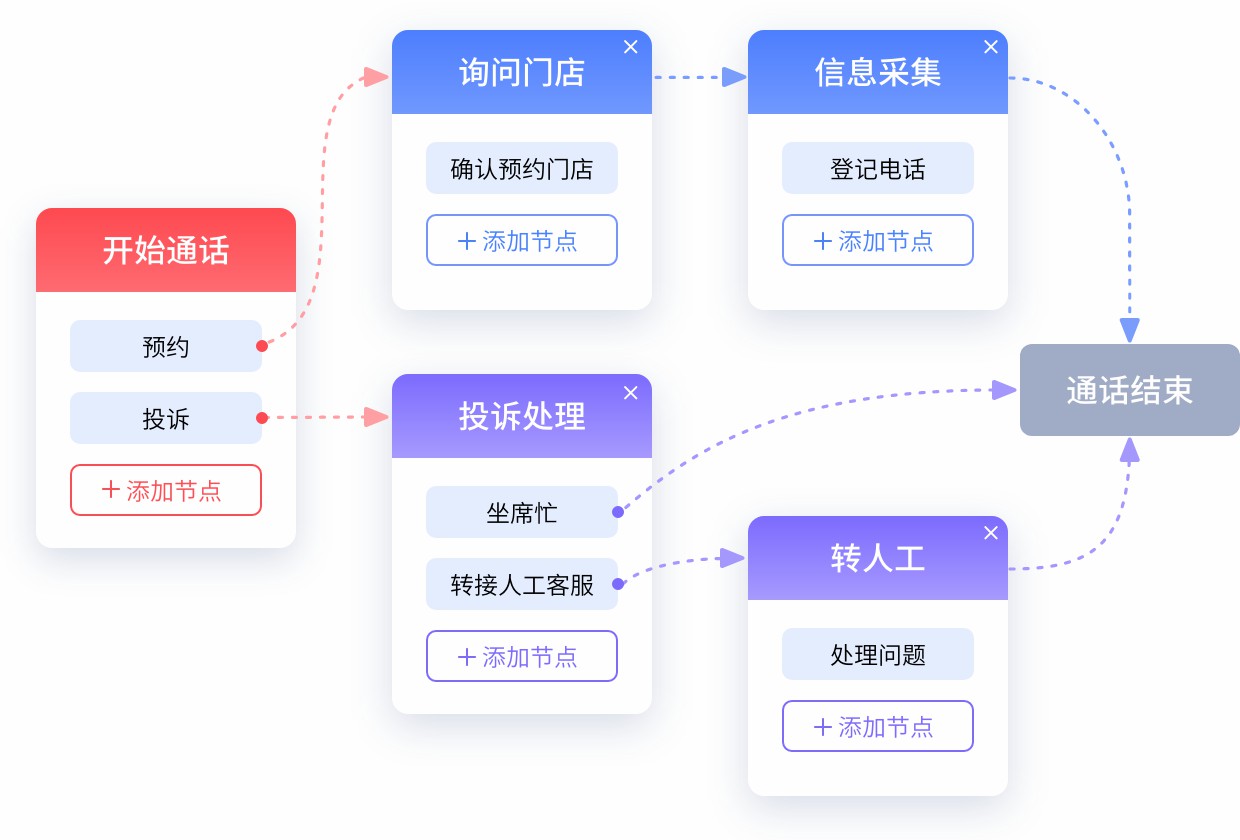
四、决策层:多轮对话管理的核心运行机制
单次语音识别与语义理解仅能支撑单轮人机交互,而AI语音电话机器人的核心优势是支持流畅的多轮连续对话。多轮对话的核心难点在于上下文关联、对话状态延续、逻辑闭环衔接,这一功能由对话管理模块承接,是连接NLU语义理解与语音输出的核心决策中枢。
(一)对话上下文存储与状态延续
人类的多轮沟通具备极强的连贯性,后续对话往往会省略前文提及的主体、条件、需求等信息,依托上下文完成沟通。机器想要实现自然多轮对话,必须具备上下文记忆与状态延续能力。
对话管理模块会实时存储每一轮对话的核心数据,包括用户识别意图、提取的实体信息、对话交互记录、当前对话节点等内容。所有存储信息会形成专属的对话上下文数据库,贯穿整通电话交互全程。
在后续轮次对话中,NLU模块解析用户新的表述时,会自动调取上下文存储信息,补全当前对话缺失的内容,关联前文诉求,避免出现每轮对话独立割裂、重复提问、逻辑断层的问题,保障对话的连贯性。
同时,模块具备动态记忆清理能力,针对无效、过期的对话信息会自动弱化处理,聚焦当前核心对话诉求,避免冗余信息干扰对话决策。
(二)对话意图追踪与逻辑纠错
多轮对话过程中,用户的诉求可能出现延续、切换、补充、变更等多种情况,对话管理模块具备实时意图追踪能力,可动态捕捉用户诉求变化,适配对话节奏。
1、意图延续处理。当用户后续对话为前文诉求的补充提问、细节咨询、确认核实内容时,模块可判定为同一对话链路,延续原有对话逻辑,针对性解答细节问题,无需重复确认核心诉求。
2、意图切换识别。当用户主动更换对话主题、提出全新诉求时,模块可快速识别意图变更,实时更新对话状态,切换至全新的对话链路,适配用户新的沟通需求。
3、对话逻辑纠错。针对用户多轮对话中出现的表述矛盾、信息冲突、逻辑混乱等情况,模块可结合上下文识别矛盾点,通过温和的交互方式核实信息、厘清诉求,保障对话逻辑的严谨性。
(三)对话应答策略生成机制
在完成语义理解与对话状态判定后,对话管理模块会根据当前对话场景、用户意图、上下文信息,生成对应的应答策略,确定机器的回复内容、提问方式、交互节奏,完成对话决策。
1、基础应答匹配。针对常规、明确的用户诉求,模块结合场景知识库,匹配对应的标准化应答内容,保证回复的准确性与规范性,快速响应用户提问。
2、主动追问补全。当用户诉求模糊、信息缺失、表述不完整时,模块不会盲目应答,而是根据当前对话节点,主动发起针对性追问,补齐所需核心信息,保障对话能够持续推进。
3、异常兜底应答。针对用户表述混乱、语义无法识别、超出场景知识范围等异常情况,模块会触发兜底应答机制,输出规范的引导话术,引导用户清晰表达诉求,避免对话中断、交互卡顿。
五、输出层:TTS语音合成实现自然语音反馈
机器完成语义理解与对话决策、生成文本应答内容后,需要通过TTS语音合成技术,将机器文本语言转化为人类可听懂的自然语音,完成交互闭环。TTS技术决定了机器人语音的自然度、流畅度、舒适度,是人机交互体验的重要组成部分。
(一)TTS文本预处理与韵律调控
TTS模块首先对决策层输出的应答文本进行预处理,优化文本适配语音输出。主要包括文本规整、多音字校正、语气适配、断句优化等操作,解决书面文本与口语表达的适配问题。
同时,模块会完成语音韵律调控,根据对话场景调整语速、语调、停顿、轻重音等韵律特征,让机器语音摆脱机械生硬的播报感,贴合人类日常沟通的语音节奏,提升交互自然度。
(二)语音生成与实时输出
预处理完成的文本会输入TTS声学模型,模型依托训练学习的语音特征,生成对应的自然人声音频信号。现代TTS模型生成的语音音色饱满、节奏自然,能够有效区分不同对话场景的语气差异,适配咨询、确认、引导等各类交互场景。
同时,TTS模块采用实时流式输出架构,可快速将生成的语音信号推送至通话链路,保障人机对话的低延迟,让交互节奏贴合人工沟通速度,无卡顿、无延迟感。
六、全链路协同:多轮对话的完整运行闭环
AI语音电话机器人的多轮对话能力,并非单一模块独立作用,而是ASR、NLU、对话管理、TTS四大核心模块,搭配各类辅助模块的全程协同联动。每一轮人机交互都是一次完整的技术闭环,多轮对话则是闭环的持续迭代与状态延续。
(一)单轮交互技术闭环流程
1、用户语音输入,硬件设备捕捉语音信号,完成降噪、分帧、特征提取等预处理操作,输出纯净语音特征数据。
2、ASR模块接收语音特征,通过声学模型与语言模型运算,完成语音转文字,输出标准化口语文本。
3、NLU模块解析文本内容,完成分词、句法分析、意图识别、实体抽取、歧义消解,精准还原用户核心诉求。
4、对话管理模块结合上下文状态、用户意图、场景规则,判定对话逻辑,生成对应的文本应答策略。
5、TTS模块将应答文本转化为自然语音,实时输出至通话链路,完成单轮人机交互闭环。
(二)多轮对话持续迭代逻辑
单轮交互完成后,对话管理模块会将本轮所有交互数据存入上下文记忆库,更新对话状态与对话节点,为下一轮交互提供语境支撑。当用户发起新一轮语音表达时,系统会重复上述闭环流程,同时关联历史对话信息,实现连贯的多轮沟通。
在多轮迭代过程中,系统会动态更新对话状态、补充实体信息、追踪意图变化、调整应答节奏,全程保持对话逻辑连贯、诉求清晰、应答精准,最终形成完整的多轮对话交互体系。
七、技术链路的核心优化方向与能力边界
(一)核心技术优化方向
随着人工智能技术的持续迭代,AI语音电话机器人的全链路技术能力也在不断优化升级。整体优化方向集中在口语适配、语义深度、语境感知、交互自然度四大维度。
1、极致口语适配优化。技术迭代持续提升对各类口语场景的适配能力,进一步兼容口音、语速波动、碎片化表达、即兴表述等复杂场景,降低识别与理解偏差。
2、深度语义理解优化。模型逐步强化隐含语义、情绪语义、复杂逻辑语义的解析能力,摆脱字面理解局限,更贴合人类的思维逻辑与沟通习惯。
3、长上下文对话优化。持续提升长时多轮对话的记忆能力与逻辑梳理能力,适配长时间、多节点、多诉求的复杂通话场景,避免上下文遗忘、逻辑混乱等问题。
4、个性化交互优化。通过模型迭代优化语音韵律、应答语气、交互节奏,让机器人的应答方式更灵活、更自然,弱化机器感,提升人机交互体验。
(二)技术能力边界说明
现阶段AI语音电话机器人的技术链路已能够适配绝大多数常规电话对话场景,但仍存在明确的能力边界。对于无逻辑、无明确诉求的碎片化表达、超出通用认知的专业冷门内容、高度隐晦的情绪化对话,机器的识别与理解精准度会有所下降。
同时,机器的语义理解始终依托训练语料与场景逻辑,无法实现人类的自主思考、情感共情与创造性应答,所有交互内容均基于技术模型的逻辑运算与规则匹配,这也是当前智能语音交互技术的固有边界。
技术的持续迭代正在不断缩小能力边界,通过模型优化、语料更新、场景适配,机器人的对话智能化、自然化、精准化水平还在持续提升。