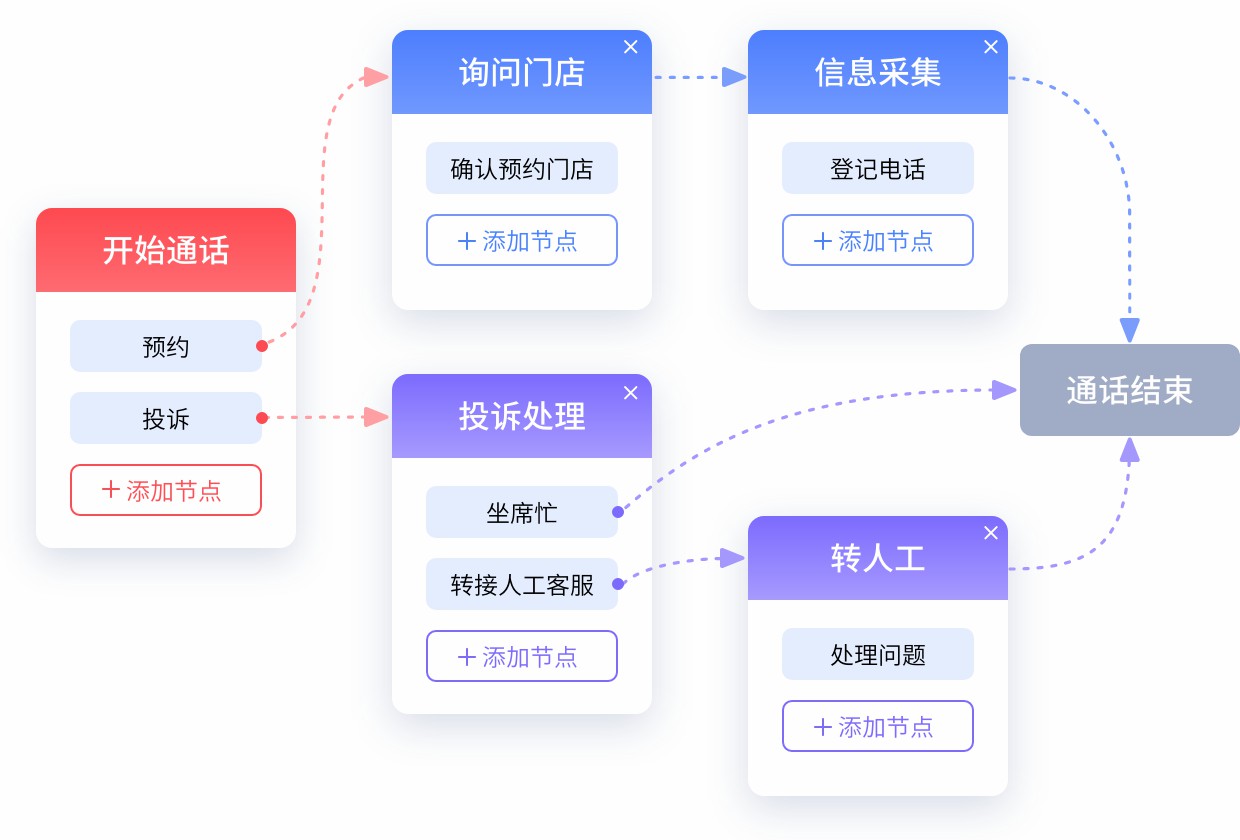
很多企业在部署语音机器人后会发现,虽然接通率上去了,但“有效交互率”很低。用户往往听到第一句就挂断,或者在交互两句后因为机器人听不懂人话而失去耐心。
根本原因在于,大多数企业的脚本设计思维还停留在 “IVR 问卷时代”,而非 “AI Agent 时代”。

一、 核心认知:为什么你的回访机器人像“查户口”?
1. 传统“单线式”脚本的致命缺陷
传统的脚本设计本质上是一棵僵化的“决策树”:
- 线性逻辑:机器人只能按 A → B → C 的顺序提问。如果用户在回答 A 时突然问了 C 的问题,机器人就会“卡壳”或强行把话题拉回 A,这种体验极差。
- 关键词匹配的局限:传统技术依赖关键词捕捉(如“满意”、“还可以”)。但在真实通话中,用户可能会说:“这也就是凑合用吧,反正没坏。” 这种口语化表达,传统脚本很难精准归类。
- 缺乏记忆:机器人无法理解上下文,一旦被打断,往往会重复上一句问题,导致用户情绪爆发。
2. 融合模式:从“填表”转向“服务闭环”
新一代的 AI 语音回访 不仅仅是为了收集一个“满意度评分”,它的核心目标是 “服务闭环”。
这意味着脚本设计必须具备双重能力:
- 严谨的业务边界:必须按 SOP 流程完成核心信息收集(如:是否满意、具体原因、是否解决)。
- 拟人的交互弹性:必须能像真人一样处理打断、插话、反问,并理解复杂的情绪和方言。
二、 架构设计:融合模式下的脚本“骨架”
为了实现上述目标,我们在设计脚本时,推荐采用 “可视化流程编排(SOP) + 大模型意图口袋(LLM)” 的融合模式。
这种模式将脚本分为“骨架”和“血肉”两部分:
1. 骨架:MPaaS 可视化流程编排(主控逻辑)
这是业务的底线。利用 MPaaS 平台的流程编排能力,我们将回访任务拆解为若干个核心节点。
- 作用:确保机器人始终知道“现在的任务是什么”(例如:确认满意度),并且在偏离话题后能够有策略地拉回主线。
- 关键配置:
- 主流程节点:身份确认 → 满意度询问 → 不满意归因 → 结束语。
- 业务系统挂载:在“身份确认”节点前,通过 API 实时调取 CRM 或 订单系统数据(如:客户刚修了什么电器、维修师傅是谁),为生成个性化开场白做准备。
2. 血肉:大模型泛化理解(交互层)
这是体验的关键。我们不再穷举所有关键词,而是将对话的理解权交给大模型。
- 语义泛化:DeepSeek/GPT 等大模型能够理解“虽然师傅迟到了,但修得还行”这种复杂的混合意图,并将其精准判定为“服务一般”但“结果满意”。
- 意图口袋:当用户在这个节点没有直接回答问题,而是说了一堆吐槽时,大模型能自动提取关键信息(如:抱怨收费高、抱怨态度差),直接填入工单字段,无需机器人傻傻地再问一遍“那您对收费满意吗?”。
三、 实操拆解:高完成度的“满意度回访”脚本怎么写?
我们将脚本切分为三个关键模块:唤醒式开场、意图分支处理、打断与跳跃机制。以“某知名家电品牌售后维修回访”为例:
1. 开场设计:拒绝“我是机器人”,采用“场景唤醒”
痛点: 传统开场白通常是“您好,我是XX客服,想耽误您一分钟……”,这种话术的挂断率极高,因为用户感知到的是“骚扰”。
优化策略: 只有让用户感知到“这个电话和我有关系”,才能留住注意力。利用 API 节点,在拨出电话前先从 CRM/工单系统获取具体数据。
传统通用版: “您好,我是某某电器的客服机器人,给您做个回访,请问您对服务满意吗?” (用户心理:推销?诈骗?挂断!)
场景唤醒版(推荐): “李先生您好,这里是某某电器服务中心。看到昨天刘师傅上门帮您修好了滚筒洗衣机,想跟您确认一下,今天机器使用都正常吗?” (用户心理:哦,是昨天那个师傅的事,那个洗衣机确实修过了。——场景唤醒成功)
2. 交互核心:主流程与智能分支
这是脚本的骨架。我们需要在流程画布中预设“满意”与“不满意”的两条主路径。
分支 A:满意/一般(快速闭环)
如果用户回答“挺好的”、“没啥问题”、“这就那样吧”,大模型将其归类为 Positive/Neutral。
- 策略:简单致谢,不纠缠。
- 进阶技巧:可根据业务规则植入弱营销。例如,如果系统判断该用户保修期即将结束,可顺势提醒:“好的,打扰了。另外提醒您,您的整机保修下个月到期,近期使用有疑问随时联系我们。”
分支 B:不满意(大模型归因 + 安抚)
这是 AI Agent 真正发挥价值的地方。传统机器人会机械地问“是态度不好还是技术不好?请按1...”,而 Agent 能够听懂用户的吐槽。
【模拟对话】
机器人: “今天机器使用都正常吗?” 用户: “能用是能用,但那个师傅太不讲究了,进门鞋套也不穿,弄得地板脏死了,而且收费还没给发票!”
后台处理逻辑:
1. 情绪识别:愤怒(高风险)。
2. 意图提取:
- 投诉项1:服务规范(未穿鞋套)。
- 投诉项2:收费合规性(未开发票)。
- 维修结果:正常(“能用是能用”)。
机器人应答(自动生成): “非常抱歉李先生,给您添麻烦了。关于师傅没穿鞋套和未开发票的问题,我们已经记录下来,稍后会有专人跟进处理。那除此之外,洗衣机现在的运行声音和脱水功能都正常吗?”
解析: 机器人没有机械地问“请问哪里不满意”,而是直接复述了用户的痛点,并进行了安抚。
3. “打断与跳跃”机制:处理非线性对话
用户不是只会回答问题的考生,他们随时会反问或打岔。我们需要在 MPaaS 平台配置 “全局意图”。
【场景模拟:反问保修政策】
机器人: “请问您对刘师傅的服务态度满意吗?” 用户(打断): “哎对了,我换的这个电机到底是保修一年还是三年啊?”
处理逻辑:
1. ASR 抢话:检测到用户说话,机器人立刻停止播报。
2. 意图识别:命中知识库中的【保修政策查询】意图。
3. RAG 检索生成:调用知识库答案“核心部件保修三年”。
4. 上下文记忆与拉回:回答完问题后,必须把话题拉回主流程。
机器人应答: “李先生,根据政策,您更换的核心电机是保修三年的,您可以放心使用。那在这个基础上,您对刘师傅昨天的服务态度还满意吗?”
核心价值: “回答问题 → 拉回主线”。这个“拉回”动作是设计脚本时最容易被忽略,但却是保证问卷完成率的关键步骤。
四、 兜底与闭环:机器人解决不了怎么办?
一个成熟的企业级应用,必须假设“AI 并不是万能的”。在脚本设计中,必须预埋异常处理机制和数据流转逻辑。
1. 边界识别:什么时候该“举手投降”?
不要试图让机器人解决所有问题。我们建议配置以下三种强制转人工策略:
- 情绪触发:当大模型识别到用户情绪为“愤怒”或出现辱骂词汇时,立即停止解释,直接转接人工专席。
- 未知意图触发:当用户连续两次提出机器人无法回答的问题时,触发兜底话术,避免机器人反复说“我没听懂”。
- 高风险业务触发:涉及退款、赔偿、媒体曝光威胁等敏感话题,直接路由至专家组。
2. 数据闭环:回访的终点不是“挂断”,而是“工单”
很多企业的误区是:机器人打完电话,生成一段录音和文字实录就结束了。这是对数据的浪费。
最佳实践是实现“对话即填单”:
- 结构化归档:脚本设计时,要将对话中的非结构化信息(口语吐槽)映射为业务系统的结构化字段。
- 用户原话:“师傅没穿鞋套,搞得地很脏。”
- 系统字段:满意度=不满意,归因标签=服务规范/卫生问题,紧急程度=一般。
- 自动化流转:
- 满意 → 系统自动关闭服务单,归档绩效。
- 不满意 → MPaaS 平台调用 API 自动创建一条新的“投诉跟进工单”,并派发给对应的网点经理。
五、 结语:好脚本是“养”出来的
语音机器人回访项目的成功,30% 靠技术(模型能力),70% 靠运营(脚本打磨)。
不要期望第一版脚本就能达到 90% 的完美交互率。真正的实操路径是:
1. MVP 验证:先跑通“满意”的主流程,确保 80% 的普通用户能顺畅走完。
2. 数据驱动优化:每周复盘“异常挂断”和“转人工”的录音,挖掘用户的新问法,补充进大模型的意图口袋。
3. 个性化迭代:从统一话术,逐渐进化到针对不同客群(新客、老客、VIP)设计不同的开场白。
拒绝“查户口”式的冷漠回访,用“可视化编排 + 大模型”的设计思维,让每一次 AI 呼叫都成为体现企业服务温度的机会。
FAQ:语音机器人项目落地常见问题
Q1:使用大模型生成回答,会不会出现“幻觉”(胡说八道)?
A: 会,所以不能让大模型“裸奔”。在企业级脚本中,我们通常限制大模型仅用于意图理解和基于知识库(RAG)的受控生成。对于核心业务(如承诺赔偿、退款规则),严禁大模型自由发挥,必须通过预设的标准话术或规则引擎来输出。
Q2:机器人能听懂方言吗?
A: 目前主流的 ASR(语音识别)引擎配合大模型语义理解,对带有口音的普通话(如川普、广普)识别率已经非常高(90%以上)。如果是纯正的方言(如温州话、闽南语),目前仍建议在脚本中配置“听不懂则转人工”的兜底策略。
Q3:配置这样一套复杂的脚本需要多久?
A: 基于合力亿捷 MPaaS 这类可视化编排平台,如果业务SOP清晰,基础版本的搭建通常在 1-3天 内即可完成。更耗时的是前期的接口打通(获取业务数据做开场白)和后期的坏例调优。
Q4:如何判断我的业务适不适合用语音机器人?
A: 两个标准:一是高频重复(如通知、确认、初筛、简单回访);二是流程相对标准。如果你的回访主要是为了“安抚极度愤怒的客户”或“进行复杂的顾问式销售”,那么真人服务目前仍是不可替代的。