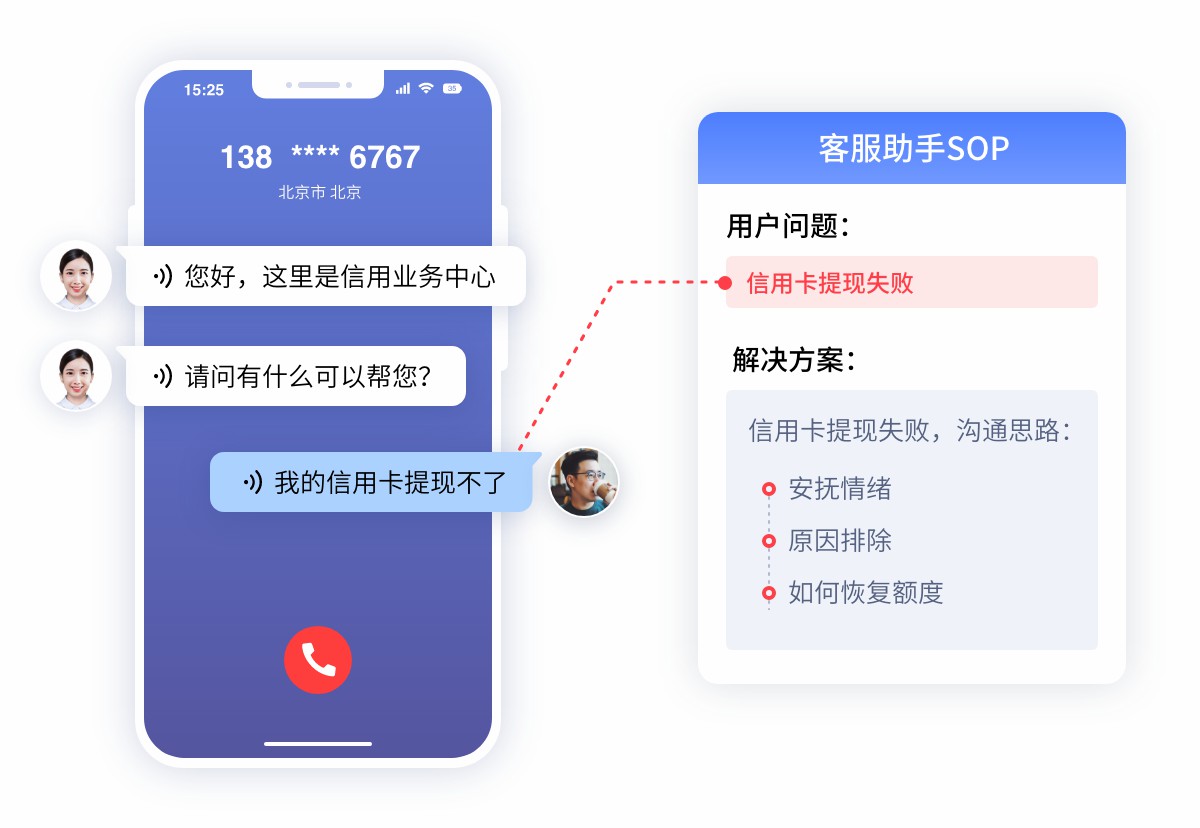
引言:“答非所问”的本质是意图理解不足
当用户询问“我的订单到哪了”,智能客服却回答“我们的发货时间是1-3天”,这种“答非所问”的现象暴露了当前语音机器人普遍存在的意图识别偏差问题。据行业分析,超过60%的智能语音交互失败案例源于对用户真实意图的理解偏差,而非语音识别错误。企业每天产生的大量历史通话录音,正是解决这一难题的数据金矿。通过系统化挖掘和利用这些数据,可以有效提升机器人的语义理解能力,根治理解错位问题。

第一步:数据清洗与聚类分析——从海量录音中定位核心问题
智能语音机器人表现不佳的根本原因往往在于训练数据的质量不足或覆盖面不全。历史通话录音中蕴含着用户真实的表达方式、业务场景和问题模式,但这些数据必须经过系统处理才能发挥价值。
实施方法:
通话转写与结构化:采用语音转写技术将历史录音转化为文本数据,并按对话轮次、通话时长、业务类型等维度进行结构化打标
问题聚类分析:利用无监督学习算法对转写文本进行聚类,识别高频问题类型和用户常见表达方式
关键指标识别:重点关注转人工率高的对话片段、用户重复询问的问题以及负面情绪集中点,这些通常是机器人理解能力的薄弱环节
第二步:上下文感知训练——构建多轮对话理解能力
传统意图识别模型常将用户每次发言作为独立输入进行处理,忽略了对话的连续性,这是导致“答非所问”的主要原因之一。真实场景中,超过40%的用户查询依赖于上文语境。
技术要点:
对话状态追踪:建立能够记忆和更新对话关键信息的机制,如用户已提供的订单号、选择的服务类型等
上下文向量构建:将对话历史编码为语义向量,作为当前查询的理解背景
指代消解增强:专门训练模型理解“这个”、“那个”、“它”等指代词的所指对象
第三步:强化学习与持续优化——建立自进化机制
一次性的模型训练无法适应不断变化的用户语言习惯和业务需求。基于历史数据的强化学习可以让机器人在实际交互中持续优化。
实施框架:
反馈循环构建:收集每次交互后的人工纠正记录、用户满意度评分和对话完成情况
动态权重调整:根据反馈数据调整不同意图识别路径的置信度权重
新意图发现:定期分析未被现有意图覆盖的用户表达,发现新的意图类别
A/B测试验证:对新优化的模型进行对比测试,确保性能提升后再全面部署
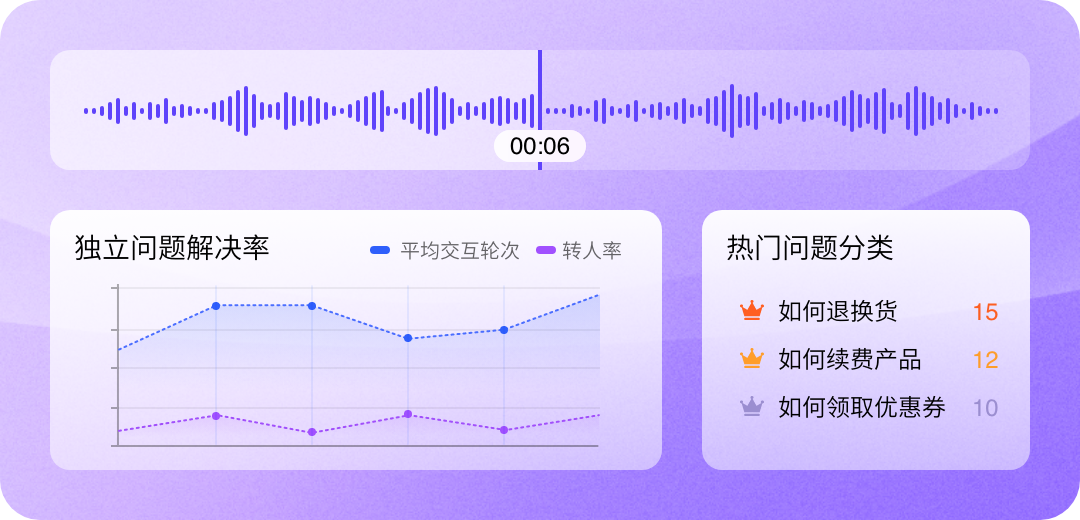
效果评估与关键指标
要科学评估三步训练法的实施效果,企业需关注一套多维度的指标体系。这些指标不仅反映机器人理解能力的提升,更直接关联业务价值。
在意图理解维度,核心指标是意图识别准确率。通过历史数据训练,该指标通常能从初期的60%-70%提升至85%-95%,这意味着机器人因误解而答非所问的情况将减少三分之二以上。
在对话效率维度,关键指标是平均对话轮次和单次解决率。优化后的对话流程更加精准,平均对话轮次可减少30%-50%,单次交互内解决问题的比例大幅提升,避免了用户反复追问的冗长循环。
在资源与成本维度,直接衡量指标是转人工率和运营成本。有效的训练能使转人工率降低35%-55%,将大量简单、重复性问题拦截在自动化流程中。相应地,单次服务成本可获得显著优化。
根据中国信息通信研究院的相关研究,系统化地采用数据驱动的优化方法,是智能体效能提升的关键。这些指标的协同改善,共同构成了机器人从“勉强可用”到“高效可靠”的证明,并最终转化为服务质量和运营效率的双重提升。
实施建议与常见挑战
在实际实施过程中,企业可能面临以下挑战:
数据安全与隐私保护
历史通话数据包含敏感客户信息,必须进行严格的匿名化处理。建议采用差分隐私技术或联邦学习框架,在不暴露原始数据的情况下进行模型训练。
跨部门协作障碍
意图训练涉及客服、IT、数据科学等多个部门,需要建立明确的协作流程和责任人制度。定期召开跨部门会议,确保业务需求与技术实施对齐。
迭代周期管理
意图优化不是一次性项目,而应成为常态化的运营工作。建议设立专门的机器人训练团队,每周分析表现数据,每月进行模型迭代。
结语
利用历史录音数据优化智能语音机器人的意图理解能力,已成为企业提升客户服务质量和效率的关键路径。通过“数据清洗与聚类→上下文感知训练→强化学习优化”这三步方法,企业可以系统性地解决“答非所问”难题,打造真正理解用户需求的智能交互体验。
行业内的实践表明,持续的数据驱动优化能让智能语音机器人在6-9个月内达到可商业部署的成熟度。合力亿捷的智能语音解决方案也基于类似方法论,通过深度挖掘对话数据价值,结合多轮对话管理和持续学习机制,帮助企业构建更精准、更自然的语音交互体验。
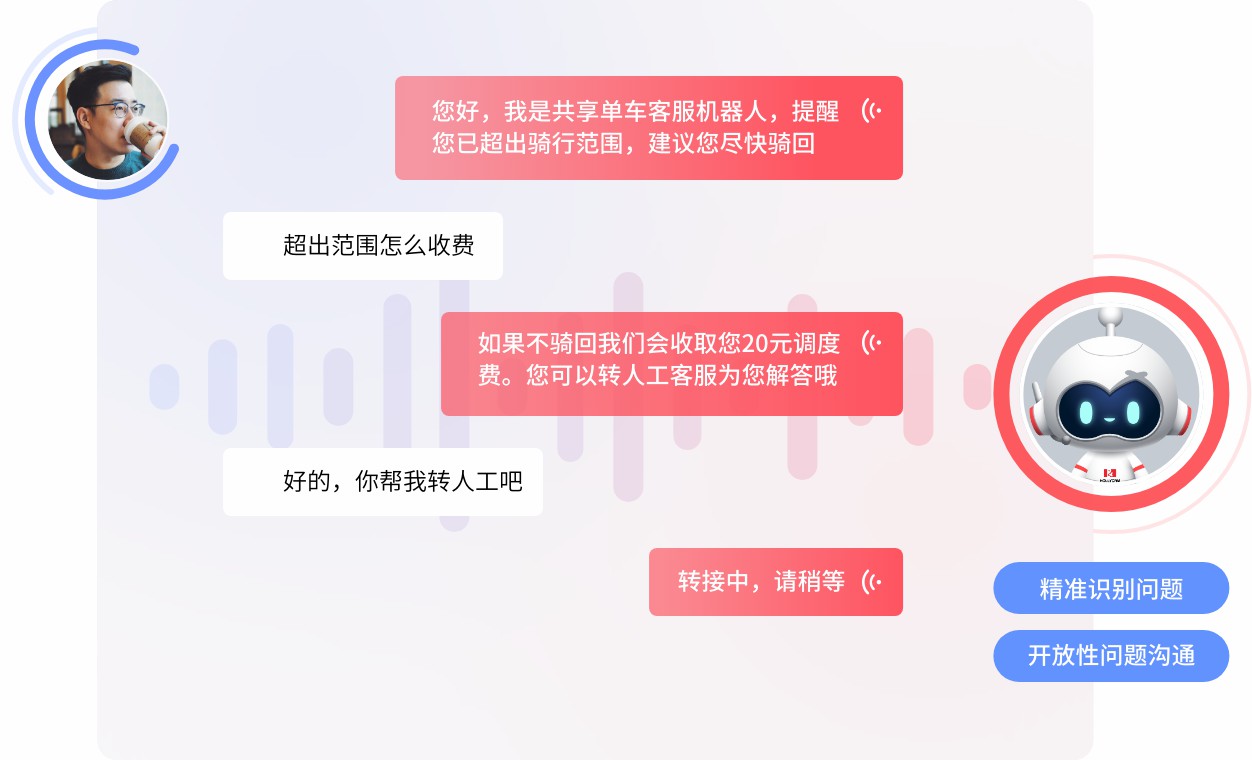
常见FAQ
1. 历史录音数据需要多大样本量才能开始训练?
建议至少准备5,000-10,000条有效通话记录作为初始训练集。重点不在于绝对数量,而在于数据的多样性和代表性,应覆盖主要业务场景和用户类型。
2. 训练后的意图识别准确率能达到什么水平?
经过系统化训练,在明确业务场景下,意图识别准确率通常可从初期的60-70%提升至85-95%。复杂场景或多轮对话的理解精度会相应降低,需持续优化。
3. 多久需要重新训练一次意图识别模型?
建议建立季度常规更新机制,每月进行小幅调整。当业务发生重大变化、推出新产品或发现识别准确率持续下降时,应立即启动专项重新训练。
资料来源
中国信息通信研究院,《政务智能体发展研究报告(2025年)》
《2025年AI语音助手智能家居场景语音交互意图识别准确率提升报告》
行业技术白皮书:《智能客服上下文感知与意图预测最佳实践》