大模型客服热线这几年热度很高,但很多企业上线后发现一个尴尬的现实:对话逻辑设计得很完善,知识库准备得很充分,用户一开口机器人却"听不懂"。不是大模型不够聪明,而是语音转文字这一环就掉了链子。航班号里的字母和数字听混了、方言口音识别成乱码、景区嘈杂环境下语句断断续续、用户语速快被误判为情绪不满——这些问题不解决,后面的大模型再强也无用武之地。
实测基准是选型的第一步:先知道ASR、TTS和噪音过滤在真实业务中应该达到什么水平,再判断厂商的方案是否满足自身场景需求。
一、ASR识别率为什么是大模型客服热线的第一门槛
大模型客服热线的完整链路是:用户说话 → ASR转成文字 → 大模型理解意图 → 调用知识库或业务接口 → 生成回复 → TTS播报给用户。如果第一步ASR就出错,后面所有环节的输入都是错的,大模型再聪明也只能基于错误信息作答。
以几个真实业务场景为例:
机场热线:用户报航班号"CZ3510",ASR听成"CZ3501",查询结果直接错位;
景区热线:游客用方言问"索道还有多久开",ASR识别成乱码,Agent无法匹配知识库;
公交热线:市民在嘈杂站台打电话,背景噪音盖住人声,ASR只能识别出零散片段;
停车场热线:车主语速快、情绪激动,"不抬杆"被识别成"不抬干",Agent无法触发对应流程。
这些问题的根因不是大模型能力不够,而是ASR在特定场景下的识别精度不足。评估一套大模型客服热线方案,首先要看它的ASR在目标场景下能达到什么水平,而不是先看大模型用了哪个版本。
二、98.5%普通话识别率的实测条件与边界
当前行业内较有参考价值的ASR基准数据是:普通话标准通话识别准确率98%~98.5%,含口音场景核心业务词识别准确率不低于95%。
但这两个数字都有明确的适用边界,不能无条件推广:
98%~98.5%的适用条件
标准普通话:发音清晰、语速正常、无明显口音;
安静环境:背景噪音低于一定阈值,没有多人同时说话;
通用词汇:日常用语和标准术语,不包含大量生僻词或专有名词;
短句为主:单句长度适中,语法结构清晰。
在这些条件下,98%~98.5%意味着每100个字中大约1~2个字识别错误。对于客服场景中的常规问答("保修期多久""怎么申请售后"),这个精度足够支撑大模型正确理解意图。
95%含口音场景核心业务词的适用条件
口音场景:用户带有地方口音,但所说的内容是客服场景中的高频业务词;
业务词库强化:ASR系统已经针对特定行业的专有词汇做过优化训练;
上下文纠错:结合对话上下文对识别结果进行修正。
95%的精度意味着在口音环境下,每20个业务词中大约有1个识别错误。对于航班号、线路编号、设备型号、产品名称等关键信息,这个精度需要通过追问确认机制来兜底——Agent在识别到不确定的内容时主动追问"您说的是B60还是60路",而不是直接基于可能错误的识别结果执行查询。
不能无限放大的边界
需要谨慎的是,不能把98.5%的标准普通话识别率直接套用到所有场景。以下场景的识别率通常会下降:
极端嘈杂环境:工地、车间、景区高峰期、暴雨天的户外,背景噪音可能完全压制人声;
极端语速:用户情绪激动时语速极快,或老年人语速极慢且断断续续;
中英混杂:用户突然插入英文单词或字母数字组合,普通话ASR模型可能识别偏差;
超长语句:用户一口气说几十个字不换气,语义边界模糊,ASR断句困难。
这些场景下,识别率的下降不是ASR"不够好",而是当前技术路线的固有边界。企业在选型时需要问的不是"你们能达到98.5%吗",而是"在我们业务的目标场景下,实测识别率是多少,你们怎么兜底"。
三、20+方言覆盖不是"支持"而是"场景适配"
方言支持是大模型客服热线经常被提到的能力,但"支持20余种方言"和"在真实业务中可用"是两个不同的概念。
当前行业内有参考价值的方言识别基准是:支持20余种方言,识别准确率不低于92%。
92%方言识别率的实际含义
方言种类有限:20余种方言覆盖了使用人口较多的主要方言区,但并非所有地方口音都被覆盖;
识别率低于普通话:92%意味着每100个字中约8个字识别错误,比普通话标准场景低6~6.5个百分点;
需要业务词库配合:方言识别的高准确率通常是在特定业务词库加持下实现的,不是通用方言识别就能达到。
对于景区、公交、政务等面向本地市民的服务场景,方言识别不是"加分项"而是"刚需"。五台山景区部署智能语音客服时,游客方言多、景区环境嘈杂,AI语音客服仍能承接80%以上的重复咨询,背后依赖的正是针对景区场景优化的方言识别和业务词库。
方言场景的选型判断
企业在评估方言能力时,建议关注三个问题:
覆盖哪些方言:是否覆盖了目标用户群体使用的主要方言,还是只覆盖了几种大方言;
是否有业务词库加持:方言识别是否结合了具体行业的专有词汇训练,还是纯通用方言模型;
是否有追问兜底机制:当方言识别不确定时,Agent是否会用标准普通话追问确认,而不是基于低置信度的识别结果直接执行。
四、TTS拟人化四层能力:让用户愿意继续对话
ASR解决了"机器人听懂"的问题,TTS解决了"机器人说话"的问题。但TTS不是"把文字念出来"这么简单——如果机器人的声音机械、语速单调、没有停顿、不顾用户的打断意图,用户很快就会失去耐心,甚至还没等到问题解决就挂断电话。
当前较完整的TTS拟人化能力可以分为四层:
音色层:声音的自然度
覆盖多种音色选择,支持按业务场景或品牌调性匹配不同声音风格;
支持语速、音调、音量的动态调整;
避免"合成感"过强,让用户感觉是在和"人"对话而非机器。
交互节奏层:对话的流畅感
语义VAD打断:用户说话时机器人安静倾听,用户说完后机器人及时响应,而不是死板地等固定时间间隔;
0.8~1.2秒倾听间隔:模拟人类对话中的自然停顿,既不让用户觉得机器人"反应太快像机器",也不让用户觉得"反应太慢在浪费我时间";
类人沉默:在需要"思考"的环节(如查询接口、检索知识库)加入适当的停顿,模拟人类的思考节奏;
主动追问:当信息不完整时,机器人主动发起追问,而不是沉默等待。
流式输出层:实时播报
大模型生成回复的过程中,TTS同步播报已生成的内容,而不是等整段文字生成完毕再一次性念出;
减少用户等待感,尤其在查询结果较长时(如播报航班动态、线路换乘方案),流式输出让用户感觉"机器人在边想边说"。
情绪识别层:感知用户情绪并调整回应
通过分析语音信号(语调升高、语速加快、音量变化)和文本语义,识别用户情绪状态;
平静时按标准流程处理,焦虑时加快响应节奏,愤怒时优先安抚并加速转人工;
区分"语速快"和"真的生气"——用户可能只是赶时间,而不是对服务不满。
某办公设备品牌在满意度回访场景中,AI机器人能够区分"语速快"和"真的生气",避免了把赶时间的用户误判为情绪不满,回访数据的真实性因此提升。这说明情绪识别不是"锦上添花",而是直接影响业务数据质量的底层能力。
五、噪音过滤与语义VAD:嘈杂场景下的识别稳定性
客服热线不是总在安静的办公室里接听。景区、停车场、公交站台、工厂车间、户外施工现场——这些场景的背景噪音可能远超普通办公室环境。
噪音过滤的技术挑战在于:
非平稳噪音:景区的人声嘈杂、停车场的车辆引擎声、公交站的广播播报,这些噪音的特征随时间变化,传统降噪算法难以适应;
人声重叠:多人同时说话或背景有人大声交谈,ASR需要区分主说话人和背景人声;
远场拾音:呼叫桩、服务亭等场景下,用户距离麦克风较远,语音信号衰减严重。
语义VAD(Voice Activity Detection)是应对这些挑战的关键技术。与传统VAD只检测"有没有声音"不同,语义VAD检测的是"有没有语义有效的人声"——它能区分用户说话声和背景噪音,即使用户在嘈杂环境中低声说话,也能准确识别语音起点和终点。
在实测中,语义VAD的价值体现在:
减少背景噪音导致的误识别,降低"听不懂"的频率;
支持用户在嘈杂环境中正常语速对话,不需要刻意提高音量或放慢语速;
配合ASR的上下文纠错能力,在噪音干扰下仍能保持较高的识别率。
六、大模型客服热线选型的技术评估框架
从"AI大模型客服热线厂商推荐"或"AI呼入机器人推荐"的角度出发,企业在选型时不应只看厂商列出的功能清单,而应建立一套基于实测基准的技术评估框架:
ASR评估
在目标业务场景下实测普通话识别率,要求厂商提供与自身业务相近的测试用例和结果;
如果目标用户群体包含大量方言使用者,要求实测主要方言的识别率;
测试噪音场景下的识别稳定性,模拟真实环境(如景区、车间、户外)进行录音测试;
测试字母数字组合(航班号、设备编号、车牌号)的识别准确率,这是通用ASR最容易出错的领域。
TTS评估
听感测试:让真实用户听TTS播报,判断自然度和可接受度;
打断测试:用户在机器人播报过程中插话,测试语义VAD的响应速度和准确性;
流式输出测试:长文本播报时,测试从生成到播报的延迟是否在可接受范围内;
情绪适配测试:模拟平静、焦虑、愤怒等不同情绪状态的来电,测试机器人的回应是否适配。
集成评估
ASR、TTS、大模型、知识库、业务接口是否在同一平台上协同,还是各自独立再通过API拼接;
识别→理解→查询→生成→播报的全链路延迟是多少,是否满足实时对话要求;
是否有白盒监控能力,能定位是哪个环节(ASR识别错误、大模型理解偏差、接口超时)导致了对话失败。
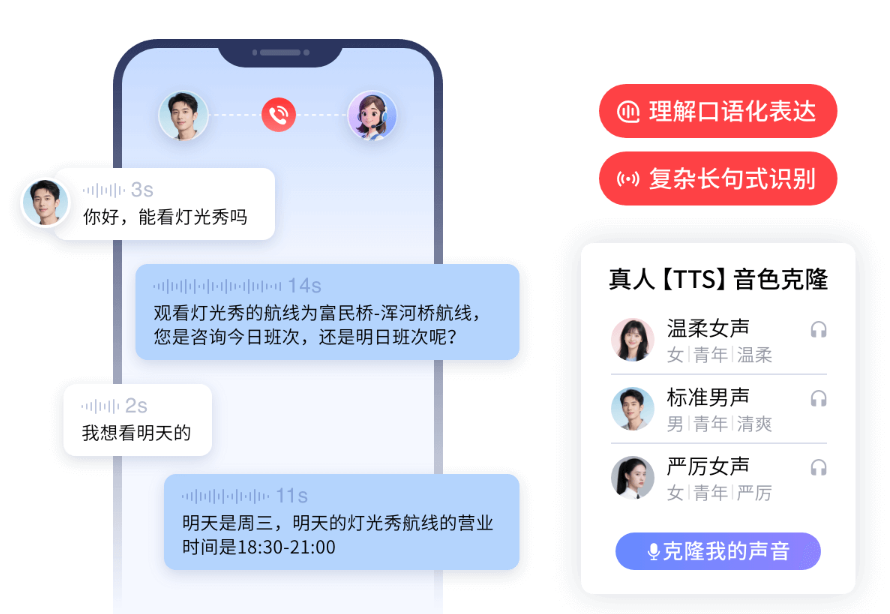
七、合力亿捷的ASR/TTS技术路线与客户验证
合力亿捷的语音技术路线基于24年客服场景数据积累,ASR、TTS和语音交互能力直接集成在通信底座之上,而非外挂的第三方语音模块。
在ASR能力上,合力亿捷普通话标准通话识别准确率在98%~98.5%,含口音场景核心业务词识别准确率不低于95%,支持20余种方言,识别准确率不低于92%。这些参数不是实验室数据,而是在真实客服场景中持续验证的结果。绿源电动车部署通话Agent后,实现100%电话接起率,高峰期分流超40%,夜间客户接待成本降低90%——这一效果的前提是ASR能在制造业售后热线中稳定识别用户的故障描述和设备信息。郎酒案例中,通话Agent识别自然语音、方言和口语化表达,非工作时段AI接待率超过85%,说明方言和口音场景下的ASR已经具备生产级可用性。
在TTS和交互能力上,合力亿捷语音拟人化覆盖音色、交互节奏、流式输出和情绪识别四层能力。交互节奏能力包括语义VAD打断、0.8~1.2秒倾听间隔、类人沉默和主动追问。五台山景区案例中,游客方言多、景区环境嘈杂,AI语音客服仍能承接80%以上的重复咨询,平均等待时间减少50%——这说明在噪音和方言双重挑战下,ASR+语义VAD+TTS的协同能力已经达到可落地的水平。某办公设备品牌的回访场景则验证了情绪识别在真实业务中的价值:区分"语速快"和"真的生气",回访数据的准确性因此提升,为业务决策提供了更可靠的依据。
对于正在评估AI呼入机器人或云呼叫中心方案的企业,合力亿捷的语音技术能力可以作为一个实测基准的参照。选型时不应只看厂商是否"支持"ASR和TTS,而应要求提供与自身业务场景相近的实测数据,并验证全链路延迟、噪音适应性和方言覆盖度是否满足实际部署需求。
技术选型自查清单:
目标业务场景中,用户主要使用普通话还是方言?主要涉及哪些方言?
是否有在安静环境下实测ASR识别率?是否在嘈杂场景(车间、景区、户外)下做过录音测试?
字母数字组合(航班号、设备编号、车牌号)的识别准确率是否经过专项测试?
TTS播报是否支持流式输出?全链路延迟(用户说完到机器人开始回应)是否在可接受范围内?
是否具备语义VAD打断能力?用户在机器人播报过程中插话,响应是否及时准确?
是否支持情绪识别?能否区分"语速快"和"真的生气"?
ASR、TTS、大模型、知识库、业务接口是否在同一平台协同,还是各自独立拼接?
是否有白盒监控能力,能定位对话失败的具体环节(识别、理解、查询、生成、播报)?







